Academy Awards Data Mining, Statistical Analysis, and Visualization Using Wikipedia and Plotly
With the Academy Awards around the corner (March 4, 2018), I decided to conduct a small analysis that would visualize the past and current best picture nominees with the intention of predicting this year's winner. I took all of the nominees from 1939-2018 and crawled each film's wikipedia page for the words 'won' and 'nominated.' This process resulted in an array of nominations and wins from hundreds of awards. After a small amount of data validation and hand correction, I plotted all the nomination and win information for each film. I also plotted the size of each film's Wikipedia page to determine whether that was a significant resource as well. The three figures below uniquely depict the data parsed from each page, and individually portray contrasting results regarding the prediction of this year's winner; though a clear winner emerges in the final plot.

Nomations and Wins
In Figure 1 below, the y-axis shows the amount of times 'nomination' appeared on the respective film's Wikipedia page, and the x-axis marks the corresponding film's year of nomination. The size of each bubble represents the amount of times 'won' appeared on a film's page, and hovering over each bubble displays all the nomination and win information about each film.
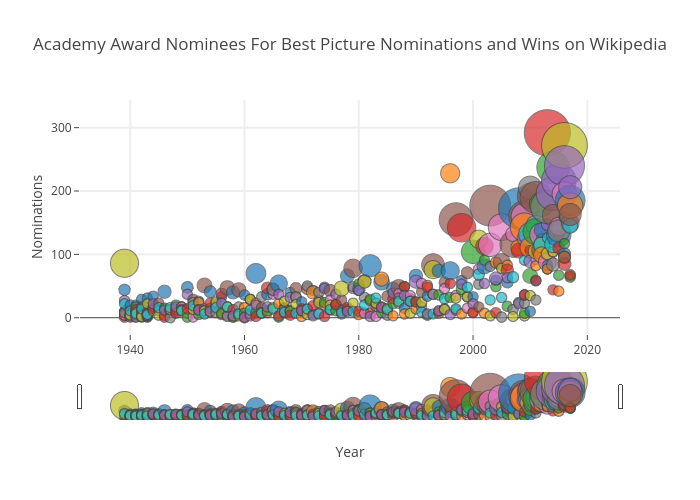
The primary takeaway from the figure above is that there is some correlation between wins and nominations regarding the win of a best picture award, however, it is not 1:1. This means that a film with the most wins at other awards is not guaranteed to win the academy award.
Wikipedia Page Size
The next figure shows films with the largest wikipedia page size compared to that year's best picture winner's Wikipedia page size (from 1978-2018). If the best picture winner had the largest page size, then the blue and teal bars are equal. There is also no 2018 blue because no winner has been announced, however, 'Call Me By Your Name' currently has the largest page. On average, the page sizes range from 100k-300k. This is html and everything from the web read.
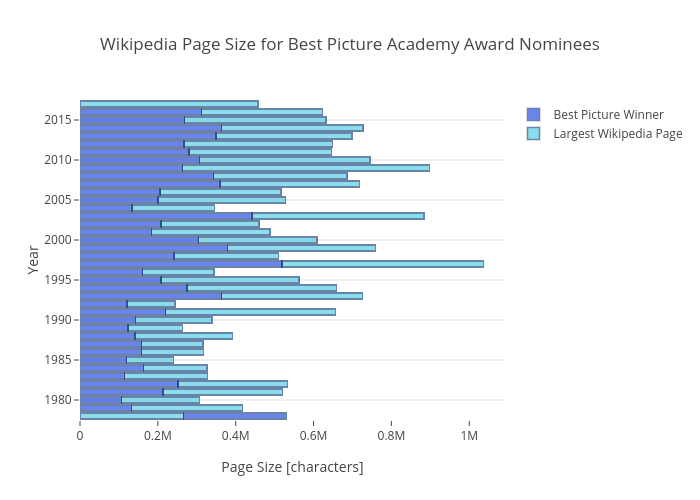
In Figure 2 above, the primary conclusion is that Wikipedia page size is very loosely correlated to the best picture winner. I hypothesize this is because many films have groundbreaking achievements in technical areas or have garner cult followings over time (Raiders of the Lost Ark, Beauty and The Beast, The Lord of The Rings Trilogy, Toy Story 3, Mad Max: Fury Road), which results in skewed page size. Therefore, the conclusion that page size will be significant in predicting this year's winner has been proven unlikely.
Win Ratio and 2018 Prediction
Using the total nominations and wins acquired from Wikipedia, I created a win ratio; which is the ratio of wins to nominations+wins. This produced a number between 0 and 1 that represented how successful a film was in reference to its nominations. I also filtered the nominees based on total wins+nominations to only include those that fell within 90% of the most-nominated film. This filtered any films that may have been nominated for a few categories and won them all - which would skew the data. This process resulted in the figure below. The green represents a successful prediction of the best picture winner, yellow represents the current year's pending win, and the red represents a failed prediction.
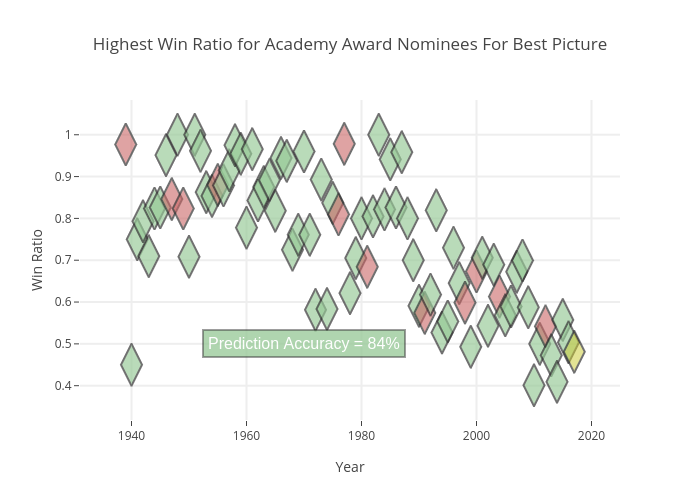
Above, in Figure 3, the outcome of this procedure is evident. With an accuracy of 84%, it can be concluded that 'Get Out' is 2018's favored film, according to this Wikipedia crawl process.

Daniel Kaluuya and Jordan Peele filming the game-room scene of Get Out.
Justin Lubin/courtesy of Universal Pictures (taken from Vulture)
Conclusion and Notes on Methodology
The figures shown above were created to visually analyze the history of the best picture nominees and winners of the Academy Awards. I entered into the experiment not knowing if the process would be successful, and the results above indicate it was. The conclusion drawn from the Wikipedia crawl is that 'Get Out' should statistically win the award for 2018. According to previous years' behavior, and according to its nominations and wins in other awards - it should be victorious. That being said, there are several notes regarding the process and inherent bias associated with my methodology:
- MATLAB was used during the analysis, but Plotly was used as the plotting tool.
- The process was completely autonomous, apart from a few hand corrections ('The Lord of the Rings' Trilogy had to be separated, 'How the West Was Won' had to be altered because it contained the word 'won' in its name, 'It's a Wonderful Life' had the same issue).
- The Wikipedia crawl may be subjective, depending on the film's following and popularity, which may skew the results as they do not necessarily reflect the opinion of the academy
- The Wikipedia data also contains previous years' wins, which means that every winner above from previous years has an inherent skew because of the 'win' of the academy award. This was overlooked because I concluded that the weight compared to other awards would be marginal (though this could be something to work on in the future).
- More awards are being created each year, so there is a trend in recent years that creates a larger skew in data (compared to years before 2000).
--Cover images courtesy of: Plotly and filmmusicreporter.com, and Mathworks
{kind=link}